v5.0 - YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations
This release implements YOLOv5-P6 models and retrained YOLOv5-P5 models. All model sizes YOLOv5s/m/l/x are now available in both P5 and P6 architectures:
- YOLOv5-P5 models (same architecture as v4.0 release): 3 output layers P3, P4, P5 at strides 8, 16, 32, trained at
--img 640
python detect.py --weights yolov5s.pt # P5 models
yolov5m.pt
yolov5l.pt
yolov5x.pt- YOLOv5-P6 models: 4 output layers P3, P4, P5, P6 at strides 8, 16, 32, 64 trained at
--img 1280
python detect.py --weights yolov5s6.pt # P6 models
yolov5m6.pt
yolov5l6.pt
yolov5x6.ptExample usage:
# Command Line
python detect.py --weights yolov5m.pt --img 640 # P5 model at 640
python detect.py --weights yolov5m6.pt --img 640 # P6 model at 640
python detect.py --weights yolov5m6.pt --img 1280 # P6 model at 1280# PyTorch Hub
model = torch.hub.load('ultralytics/yolov5', 'yolov5m6') # P6 model
results = model(imgs, size=1280) # inference at 1280Notable Updates
- YouTube Inference: Direct inference from YouTube videos, i.e.
python detect.py --source 'https://youtu.be/NUsoVlDFqZg'. Live streaming videos and normal videos supported. (#2752) - AWS Integration: Amazon AWS integration and new AWS Quickstart Guide for simple EC2 instance YOLOv5 training and resuming of interrupted Spot instances. (#2185)
- Supervise.ly Integration: New integration with the Supervisely Ecosystem for training and deploying YOLOv5 models with Supervise.ly (#2518)
- Improved W&B Integration: Allows saving datasets and models directly to Weights & Biases. This allows for --resume directly from W&B (useful for temporary environments like Colab), as well as enhanced visualization tools. See this blog by @AyushExel for details. (#2125)
Updated Results
P6 models include an extra P6/64 output layer for detection of larger objects, and benefit the most from training at higher resolution. For this reason we trained all P5 models at 640, and all P6 models at 1280.

YOLOv5-P5 640 Figure (click to expand)
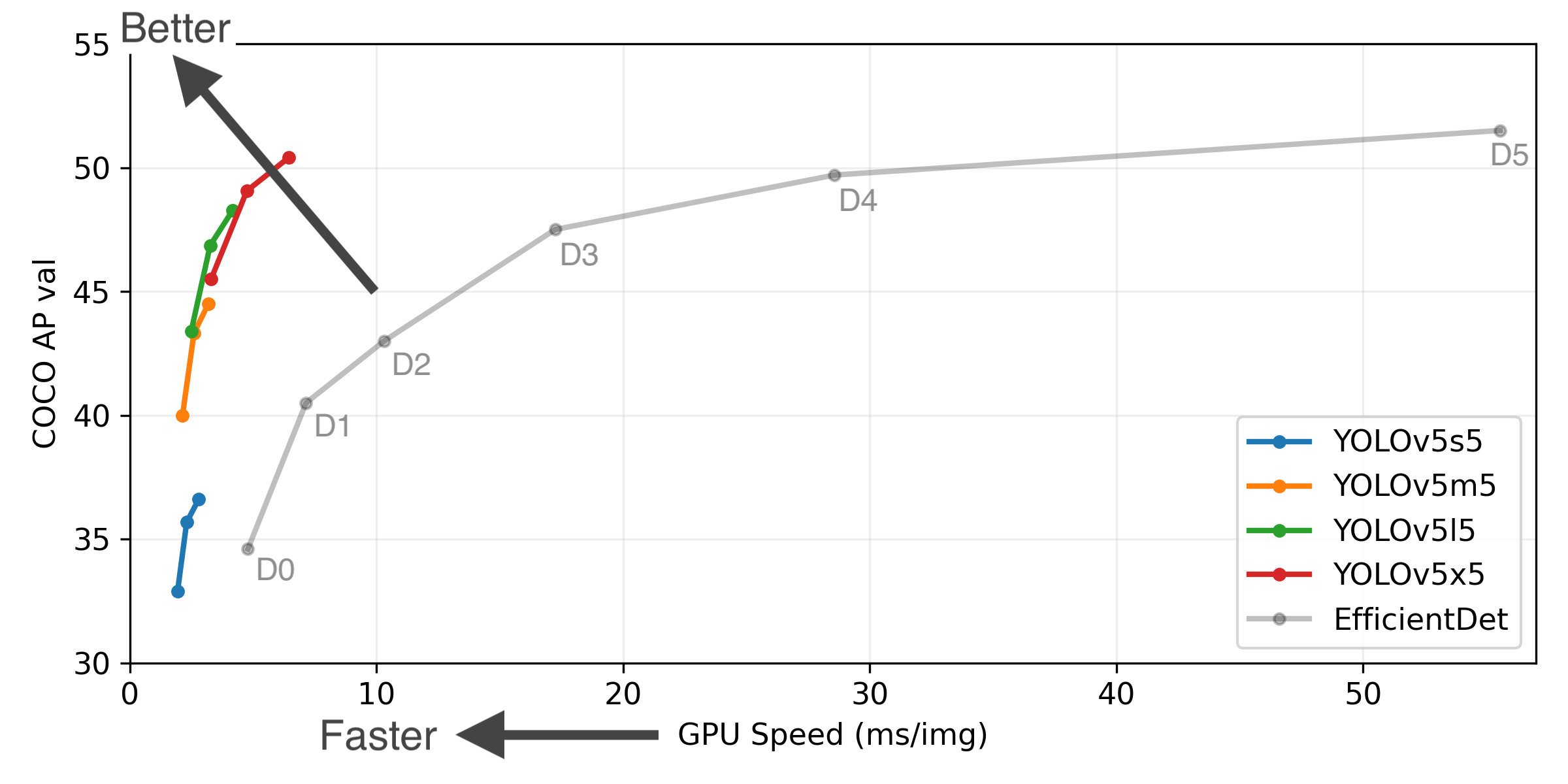
Figure Notes (click to expand)
- GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python test.py --task study --data coco.yaml --iou 0.7 --weights yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
- April 11, 2021: v5.0 release: YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations.
- January 5, 2021: v4.0 release: nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration.
- August 13, 2020: v3.0 release: nn.Hardswish() activations, data autodownload, native AMP.
- July 23, 2020: v2.0 release: improved model definition, training and mAP.
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPtest 0.5:0.95 |
mAPval 0.5 |
Speed V100 (ms) |
params (M) |
FLOPS 640 (B) |
|
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 36.7 | 36.7 | 55.4 | 2.0 | 7.3 | 17.0 | |
| YOLOv5m | 640 | 44.5 | 44.5 | 63.1 | 2.7 | 21.4 | 51.3 | |
| YOLOv5l | 640 | 48.2 | 48.2 | 66.9 | 3.8 | 47.0 | 115.4 | |
| YOLOv5x | 640 | 50.4 | 50.4 | 68.8 | 6.1 | 87.7 | 218.8 | |
| YOLOv5s6 | 1280 | 43.3 | 43.3 | 61.9 | 4.3 | 12.7 | 17.4 | |
| YOLOv5m6 | 1280 | 50.5 | 50.5 | 68.7 | 8.4 | 35.9 | 52.4 | |
| YOLOv5l6 | 1280 | 53.4 | 53.4 | 71.1 | 12.3 | 77.2 | 117.7 | |
| YOLOv5x6 | 1280 | 54.4 | 54.4 | 72.0 | 22.4 | 141.8 | 222.9 | |
| YOLOv5x6 TTA | 1280 | 55.0 | 55.0 | 72.0 | 70.8 | - | - |
Table Notes (click to expand)
- APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
- AP values are for single-model single-scale unless otherwise noted. Reproduce mAP by
python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes FP16 inference, postprocessing and NMS. Reproduce speed by
python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45 - All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
- Test Time Augmentation (TTA) includes reflection and scale augmentation. Reproduce TTA by
python test.py --data coco.yaml --img 1536 --iou 0.7 --augment
Changelog
Changes between previous release and this release: v4.0...v5.0
Changes since this release: v5.0...HEAD
Click a section below to expand details:
Implemented Enhancements (26)
- Return predictions as json #2703
- Single channel image training? #2609
- Images in MPO Format are considered corrupted #2446
- Improve Validation Visualization #2384
- Add ASFF (three fuse feature layers) int the Head for V5(s,m,l,x) #2348
- Dear author, can you provide a visualization scheme for YOLOV5 feature graphs during detect.py? Thank you! #2259
- Dataloader #2201
- Update Train Custom Data wiki page #2187
- Multi-class NMS #2162
- 💡Idea: Mosaic cropping using segmentation labels #2151
- Improving Confusion Matrix Interpretability: FP and FN vectors should be switched to align with Predicted and True axis #2071
- Interpreting model YoloV5 by Grad-cam #2065
- Output optimal confidence threshold based on PR curve #2048
- is it valuable that add --cache-images option to detect.py? #2004
- I want to change the anchor box to anchor circles, where do you think the change to be made ? #1987
- Support for imgaug #1954
- Any plan for Knowledge Distillation? #1762
- Is there a wasy to run detections on a video/webcam/rtrsp, etc EVERY x SECONDS? #1742
- Can yolov5 support rotated target detection? #1728
- Deploying yolov5 to TorchServe (GPU compatible) #1681
- Why diffrent colors of bboxs? #1638
- Yet another export yolov5 models to ONNX and inference with TensorRT #1597
- Rerange the blocks of Focus Layer into
row majorto be compatible with tensorflowSpaceToDepth#413 - YouTube Livestream Detection #2752 (ben-milanko)
- Add TransformerLayer, TransformerBlock, C3TR modules #2333 (dingyiwei)
- Improved W&B integration #2125 (AyushExel)
Fixed Bugs (73)
- it seems that check_wandb_resume don't support multiple input files of images. #2716
- ip camera or web camera. error: (-215:Assertion failed) !ss ize.empty() in function 'cv::resize' #2709
- Model predict with forward will fail if PIL image does not have filename attribute #2702
- ❔Question Whenever i try to run my model i run into this error AttributeError: 'NoneType' object has no attribute 'startswith' from wandbutils.py line 161 I wonder why ? Any workaround or fix #2697
- coremltools no longer included in docker container #2686
- 'LoadImages' path handling appears to be broken #2618
- CUDA memory leak #2586
- UnboundLocalError: local variable 'wandb_logger' referenced before assignment #2562
- RuntimeError: CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when calling
cublasCreate\(handle\)#2417 - CUDNN Mapping Error #2415
- Can't train in DDP mode after recent update #2405
- a bug about function bbox_iou() #2376
- Training got stuck when I used DistributedDataParallel mode but dataParallel mode is useful #2375
- Something wrong with fixing ema #2343
- Conversion to CoreML fails when running with --batch 2 #2322
- The "fitness" function in train.py. #2303
- Error "Directory already existed" happen when training with multiple GPUs #2275
- self.balance = {3: [4.0, 1.0, 0.4], 4: [4.0, 1.0, 0.25, 0.06], 5: [4.0, 1.0, 0.25, 0.06, .02]}[det.nl] #2255
- Cannot run model with URL as argument #2246
- Yolov5 crashes with RTSP stream analysis #2226
- interruption during evolve #2218
- I am a student of Tsinghua University, doing research in Tencent. When I train with yolov5, the following problems appear,Sincerely hope to get help, #2203
- Frame Loss in video stream #2196
- wandb.ai not logging epochs vs metrics/losses instead uses step #2175
- Evolve is leaking files #2142
- Issue in torchscript model inference #2129
- RuntimeError: CUDA error: device-side assert triggered #2124
- In 'evolve' mode, If the original hyp is 0, It will never update #2122
- Caching image path #2121
- can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first #2106
- Error in creating model with Ghost modules #2081
- TypeError: int() can't convert non-string with explicit base #2066
- [Pytorch Hub] Hub CI is broken with latest master of yolo5 example. #2050
- Problems when downloading requirements #2047
- detect.py - images always saved #2029
- thop and pycocotools shouldn't be hard requirements to train a model #2014
- CoreML export failure #2007
- loss function like has a bug #1988
- CoreML export failure: unexpected number of inputs for node x.2 (_convolution): 13 #1945
- torch.nn.modules.module.ModuleAttributeError: 'Hardswish' object has no attribute 'inplace' #1939
- runs not logging separately in wandb.ai #1937
- wrong batch size after --resume on multiple GPUs #1936
- TypeError: int() can't convert non-string with explicit base #1927
- RuntimeError: DataLoader worker #1908
- Unable to export weights into onnx #1900
- CUDA Initialization Warning on Docker when not passing in gpu #1891
- Issue with github api rate limiting #1890
- wandb: ERROR Error while calling W&B API: Error 1062: Duplicate entry '189160-gbp6y2en' for key 'PRIMARY' (<Response [409]>) #1878
- Broken pipe #1859
- detection.py #1858
- Getting error on loading custom trained model #1856
- W&B id is always the same and continue with the old logging. #1851
- pytorch1.7 is not completely support.'inplace'! 'inplace'! 'inplace'! #1832
- Validation errors are NaN #1804
- Error Loading custom model weights with pytorch.hub.load #1788
- 'cap' object is not self. initialized #1781
- ValueError: API key must be 40 characters long, yours was 1 #1777
- scipy #1766
- error of missing key 'anchors' in hyp.scratch.yaml #1744
- mss grab color conversion problem using TorchHub #1735
- Video rotation when running detection. #1725
- RuntimeError: CUDA out of memory. Tried to allocate 294.00 MiB (GPU 0; 6.00 GiB total capacity; 118.62 MiB already allocated; 4.20 GiB free; 362.00 MiB reserved in total by PyTorch) #1698
- Errors on MAC #1690
- RuntimeError: DataLoader worker (pid(s) 296430) exited unexpectedly #1675
- Non-positive Stride #1671
- gbk error. How can I solve it? #1669
- CoreML export failure: unexpected number of inputs for node x.2 (_convolution): 13 #1667
- RuntimeError: Given groups=1, weight of size [32, 128, 1, 1], expected input[1, 64, 32, 32] to have 128 channels, but got 64 channels instead #1627
- segmentation fault #1620
- Getting different output sizes when using exported torchscript #1562
- some bugs when training #1547
- Evolve getting error #1319
- AssertionError: Image Not Found ../dataset/images/train/4501.jpeg #195
Closed Issues (42)
- Can feed tensor the model #2722
- hello, everyone, In order to modify the network more conveniently based on this rep., I restructure the network part, which is divided into backbone, neck, head #2710
- Differentiate between normal banner and LED banner #2647
- 👋 Hello @Wilson-inclaims, thank you for your interest in 🚀 YOLOv5! Please visit our ⭐️ [Tutorials](https://github.com/ultralytics/yolov5/wiki\#tutorials\) to get started, where you can find quickstart guides for simple tasks like [Custom Data Training](https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data\) all the way to advanced concepts like [Hyperparameter Evolution](https://github.com/ultralytics/yolov5/issues/607\). #2516
- I got a runtimerror when I run classifier.py to train my own dataset. #2438
- RuntimeError: a view of a leaf Variable that requires grad is being used in an in-place operation. #2403
- 🌟💡 YOLOv5 Study: batch size #2377
- export.py export onnx for gpu failed #2365
- in _ddp_init_helper expect_sparse_gradient) RuntimeError: Model replicas must have an equal number of parameters. #2311
- Custom dataset training using YOLOv5 #2296
- label format #2293
- MAP NOT PRINTING #2283
- Why didn't I get results in my video test? #2277
- Label Missing: for images and labels... 203 found, 50 missing, 0 empty, 0 corrupted: 100% #2268
- Pytorch Hub inference returns different results than detect.py #2224
- yolov5x train.py error #2181
- degrees is radians? #2160
- AssertionError: Image Not Found #2130
- How to load custom trained model to detect sample image? #2097
- YOLOv5 installed failed on Macbook M1 #2075
- How to set the number of seconds to detect once #2072
- Where the changes should be made to detect horizontal line and vertical lines? Can anyone discus elaborately? #2070
- Video inference stops after a certain number of frames #2064
- Can't YOLOV5 be detected with multithreading? #1979
- I want to make a images file what divided images in test.py #1931
- different image size w/ torchscript windows c++ #1920
- run detect the result ,the Image don't have box #1910
- resume problem #1884
- Detect source as .txt error #1877
- yolov5 v4.0 tensorrt deployment #1874
- Hyperparameter Evolution: load dataset every time #1864
- Caching images problem #1862
- About Release v4.0 #1841
- @Glenn best practices for running trained YOLOv5 models in new python environments is to use PyTorch Hub. See PyTorch Hub Tutorial: #1789
- yolov5x.pt is not compatible with ./models/yolov5x.yam #1721
- Parameter '--device' doesn't work! #1706
- Thank you for your issue! #1687
- Convert the label format #1652
- Autorun not working #1599
- When model.model[-1]. export = False in export.py, coreml export failing. Please check. #1491
- Error 'AttributeError: 'str' object has no attribute 'get'' at running train.py #1479
- Docker image is not working,
torch.nn.modules.module.ModuleAttributeError: 'Hardswish' object has no attribute 'inplace' #1327
Merged Pull Requests (172)
- Tensorboard model visualization bug fix #2758 (glenn-jocher)
- utils/wandb_logging PEP8 reformat #2755 (glenn-jocher)
- torch.cuda.amp bug fix #2750 (glenn-jocher)
- autocast enable=torch.cuda.is_available() #2748 (glenn-jocher)
- Add Hub results.pandas() method #2725 (glenn-jocher)
- Update README with collapsable notes #2721 (glenn-jocher)
- Fix #2716: Add support for list-of-directory data format for wandb #2719 (AyushExel)
- Updated filename attributes for YOLOv5 Hub BytesIO #2718 (glenn-jocher)
- Updated filename attributes for YOLOv5 Hub results #2708 (glenn-jocher)
- pip install coremltools onnx #2690 (glenn-jocher)
- autoShape forward im = np.asarray(im) # to numpy #2689 (glenn-jocher)
- PyTorch Hub model.save() increment as runs/hub/exp #2684 (glenn-jocher)
- Fix: #2674 #2683 (AyushExel)
- Update README with Tips for Best Results tutorial #2682 (glenn-jocher)
- Disallow resume for dataset uploading #2657 (AyushExel)
- Speed profiling improvements #2648 (glenn-jocher)
- Add tqdm pbar.close() #2644 (zzttqu)
- PyTorch Hub amp.autocast() inference #2641 (glenn-jocher)
- PyTorch Hub custom model to CUDA device fix #2636 (glenn-jocher)
- Improve git_describe() fix 1 #2635 (glenn-jocher)
- Fix: evolve with wandb #2634 (AyushExel)
- Improve git_describe() #2633 (glenn-jocher)
- FROM nvcr.io/nvidia/pytorch:21.03-py3 #2623 (glenn-jocher)
- Remove conflicting nvidia-tensorboard package #2622 (glenn-jocher)
- Update Detections() self.n comment #2620 (glenn-jocher)
- Update detections() self.t = tuple() #2617 (glenn-jocher)
- Create date_modified() #2616 (glenn-jocher)
- Added '.mpo' to supported image formats #2615 (maxupp)
- Fix Indentation in test.py #2614 (AyushExel)
- Update git_describe() for remote dir usage #2606 (glenn-jocher)
- Remove Cython from requirements.txt #2604 (glenn-jocher)
- resume.py fix DDP typo #2603 (glenn-jocher)
- Update segment2box() comment #2600 (glenn-jocher)
- Save webcam results, add --nosave option #2598 (glenn-jocher)
- YOLOv5 PyTorch Hub models >> check_requirements() #2592 (glenn-jocher)
- YOLOv5 PyTorch Hub models >> check_requirements() #2591 (glenn-jocher)
- YOLOv5 PyTorch Hub models >> check_requirements() #2588 (glenn-jocher)
- W&B DDP fix 2 #2587 (glenn-jocher)
- W&B resume ddp from run link fix #2579 (AyushExel)
- YOLOv5 PyTorch Hub models >> check_requirements() #2577 (glenn-jocher)
- Update tensorboard>=2.4.1 #2576 (glenn-jocher)
- Enhanced check_requirements() with auto-install #2575 (glenn-jocher)
- W&B DDP fix #2574 (AyushExel)
- check_requirements() exclude pycocotools, thop #2571 (glenn-jocher)
- Update Detections() times=None #2570 (glenn-jocher)
- Add opencv-contrib-python to requirements.txt #2564 (youngjinshin)
- Supervisely Ecosystem #2519 (mkolomeychenko)
- add option to disable half precision when testing #2507 (bfineran)
- PyTorch Hub models default to CUDA:0 if available #2472 (glenn-jocher)
- Scipy kmeans-robust autoanchor update #2470 (glenn-jocher)
- Be able to create dataset from annotated images only #2466 (kinoute)
- autoShape() speed profiling update #2460 (glenn-jocher)
- Add autoShape() speed profiling #2459 (glenn-jocher)
- CVPR 2021 Argoverse-HD autodownload curl #2455 (glenn-jocher)
- labels.jpg class names #2454 (glenn-jocher)
- Update test.py --task train val study #2453 (glenn-jocher)
- Integer printout #2450 (glenn-jocher)
- DDP after autoanchor reorder #2421 (glenn-jocher)
- CVPR 2021 Argoverse-HD autodownload fix #2418 (glenn-jocher)
- CVPR 2021 Argoverse-HD dataset autodownload support #2400 (karthiksharma98)
- GCP sudo docker userdata.sh #2393 (glenn-jocher)
- AWS wait && echo "All tasks done." #2391 (glenn-jocher)
- bbox_iou() stability and speed improvements #2385 (glenn-jocher)
- image weights compatible faster random index generator v2 for mosaic … #2383 (developer0hye)
- ENV HOME=/usr/src/app #2382 (glenn-jocher)
- --no-cache notebook #2381 (glenn-jocher)
- Resume with custom anchors fix #2361 (glenn-jocher)
- Anchor override for training from scratch #2350 (glenn-jocher)
- faster random index generator for mosaic augmentation #2345 (developer0hye)
- Add --label-smoothing eps argument to train.py (default 0.0) #2344 (ptran1203)
- FROM nvcr.io/nvidia/pytorch:21.02-py3 #2341 (glenn-jocher)
- EMA bug fix 2 #2330 (glenn-jocher)
- remove TTA 1 pixel offset #2325 (glenn-jocher)
- Update Dockerfile install htop #2320 (glenn-jocher)
- Update test.py #2319 (glenn-jocher)
- final_epoch EMA bug fix #2317 (glenn-jocher)
- Fix labels being missed when image extension appears twice in filename #2300 (idenc)
- W&B entity support #2298 (toretak)
- GPU export options #2297 (toretak)
- Improved model+EMA checkpointing fix #2295 (glenn-jocher)
- Improved model+EMA checkpointing #2292 (glenn-jocher)
- Update train.py #2290 (glenn-jocher)
- Amazon AWS EC2 startup and re-startup scripts patch #2282 (glenn-jocher)
- FLOPS min stride 32 #2276 (xiaowo1996)
- Update Dockerfile with apt install zip #2274 (glenn-jocher)
- Update greetings.yml for auto-rebase on PR #2272 (glenn-jocher)
- Update minimum stride to 32 #2266 (glenn-jocher)
- Robust objectness loss balancing #2256 (glenn-jocher)
- Update inference default to multi_label=False #2252 (glenn-jocher)
- Improved hubconf.py CI tests #2251 (glenn-jocher)
- YOLOv5 Hub URL inference bug fix #2250 (glenn-jocher)
- Unified hub and detect.py box and labels plotting #2243 (kinoute)
- Add isdocker() #2232 (glenn-jocher)
- Add check_imshow() #2231 (glenn-jocher)
- Update CI badge #2230 (glenn-jocher)
- Update yolo.py channel array #2223 (glenn-jocher)
- LoadStreams() frame loss bug fix #2222 (glenn-jocher)
- TTA augument boxes one pixel shifted in de-flip ud and lr #2219 (VdLMV)
- Dynamic ONNX engine generation #2208 (aditya-dl)
- YOLOv5 PyTorch Hub results.save() method retains filenames #2194 (dan0nchik)
- YOLOv5 Segmentation Dataloader Updates #2188 (glenn-jocher)
- Amazon AWS EC2 startup and re-startup scripts #2185 (glenn-jocher)
- PyTorch Hub results.save('path/to/dir') #2179 (glenn-jocher)
- Changed socket port and added timeout #2176 (NanoCode012)
- Update utils/datasets.py to support .webp files #2174 (Transigent)
- Update requirements.txt #2173 (glenn-jocher)
- Update detect.py #2167 (ab-101)
- Update data-autodownload background tasks #2154 (glenn-jocher)
- Linear LR scheduler option #2150 (glenn-jocher)
- Update train.py batch_size * 2 #2149 (glenn-jocher)
- Update train.py test batch_size #2148 (glenn-jocher)
- LoadImages() pathlib update #2140 (glenn-jocher)
- Unique *.cache filenames fix #2134 (train255)
- Making inference thread-safe by avoiding mutable state in Detect class #2120 (olehb)
- Make normalized confusion matrix more interpretable #2114 (rbavery)
- Update plot_study() #2112 (glenn-jocher)
- Update test.py --task speed and study #2099 (glenn-jocher)
- Add variable-stride inference support #2091 (glenn-jocher)
- Add Kaggle badge #2090 (glenn-jocher)
- Add Amazon Deep Learning AMI environment #2085 (glenn-jocher)
- Add YOLOv5-P6 models #2083 (glenn-jocher)
- GhostConv update #2082 (glenn-jocher)
- W&B epoch logging update #2073 (glenn-jocher)
- Update to colors.TABLEAU_COLORS #2069 (glenn-jocher)
- Update run-once lines #2058 (glenn-jocher)
- Metric-Confidence plots feature addition #2057 (glenn-jocher)
- Add histogram equalization fcn #2049 (glenn-jocher)
- Confusion matrix native image-space fix #2046 (ramonhollands)
- Check im.format during dataset caching #2042 (glenn-jocher)
- Add exclude tuple to check_requirements() #2041 (glenn-jocher)
- data-autodownload background tasks #2034 (glenn-jocher)
- Docker pyYAML>=5.3.1 fix #2031 (glenn-jocher)
- PyYAML==5.4.1 #2030 (glenn-jocher)
- Update autoshape .print() and .save() #2022 (glenn-jocher)
- Update requirements.txt #2021 (glenn-jocher)
- Update general.py check_git_status() fix #2020 (glenn-jocher)
- Update inference multiple-counting #2019 (glenn-jocher)
- Update ci-testing.yml --img 128 #2018 (glenn-jocher)
- Update google_utils.py attempt_download() fix #2017 (glenn-jocher)
- Update Dockerfile #2016 (glenn-jocher)
- check_git_status() Windows fix #2015 (glenn-jocher)
- --verbose on final_epoch #1997 (glenn-jocher)
- Add xywhn2xyxy() #1983 (glenn-jocher)
- Update Dockerfile #1982 (glenn-jocher)
- check_git_status() asserts #1977 (glenn-jocher)
- Update train.py #1972 (Anon-Artist)
- Update autoanchor.py #1971 (Anon-Artist)
- Update yolo.py #1970 (Anon-Artist)
- Update test.py #1969 (Anon-Artist)
- Update plots.py #1968 (Anon-Artist)
- check_git_status() when not exist /workspace #1966 (glenn-jocher)
- Security Fix for Arbitrary Code Execution - huntr.dev #1962 (huntr-helper)
- prevent check_git_status() in docker images #1951 (glenn-jocher)
- Add ComputeLoss() class #1950 (glenn-jocher)
- W&B mosaic log bug fix #1949 (glenn-jocher)
- Start setting up the improved W&B integration #1948 (AyushExel)
- W&B log epoch #1946 (glenn-jocher)
- Daemon thread mosaic plots fix #1943 (glenn-jocher)
- Fix batch-size on resume for multi-gpu #1942 (NanoCode012)
- Add nn.SiLU inplace in attempt_load() #1940 (1991wangliang)
- GitHub API rate limit fallback #1930 (glenn-jocher)
- check_git_status() bug fix #1925 (glenn-jocher)
- check_git_status() improvements #1916 (glenn-jocher)
- Colorstr() updates #1909 (glenn-jocher)
- PyTorch Hub results.render() #1897 (glenn-jocher)
- Docker CUDA warning fix #1895 (glenn-jocher)
- GitHub API rate limit fix #1894 (glenn-jocher)
- Add colorstr() #1887 (glenn-jocher)
- auto-verbose if nc <= 20 #1869 (glenn-jocher)
- actions/stale@v3 #1868 (glenn-jocher)
- Add check_requirements() #1853 (glenn-jocher)
- W&B ID reset on training completion #1852 (TommyZihao)
Contributors
Glenn, AyushExel, and Wilson-inclaims