[TOC]
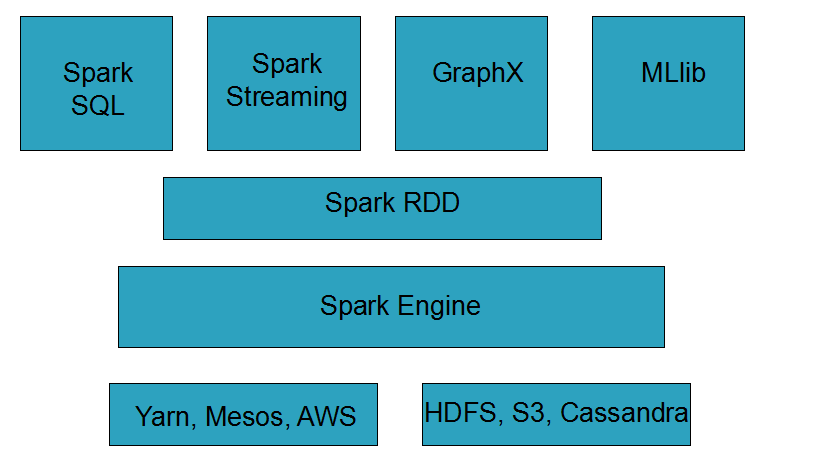
Spark是一种通用的大数据计算框架
Spark包含了大数据领域常见的各种计算框架
- Spark Core 用于离线计算
- Spark SQL 用于交互式查询
- Spark Streaming 用于实时流式计算
- Spark MLlib 用于机器学习
- Spark GraphX 用于图计算
Spark主要用于大数据的计算,而Hadoop主要用于大数据的存储(比如HDFS、HBASE),以及资源调度(Yarn)
速度快:Spark最重要的特点是基于内存进行计算,速度是MapReduce的数倍,甚至数十倍(对Spark进行适当的调优),Spark主要是基于内存但也有部分内容基于磁盘,比如shuffle
容易上手开发:Spark是基于 RDD 的计算模型,比Hadoop基于Map-Reduce的计算模型更加容易上手。可以实现各种复杂的功能,比如二次排序、分区排序取topN等复杂的操作。
超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见任务。
集成Hadoop:Spark与Hadoop进行了高度的集成,两者可以完美的配合使用。Hadoop的HDFS、HBase负责存储,Yarn负责资源调度,Spark进行复杂大数据计算,实际上Spark+hadoop是一个完美的组合。
MapReduce能够完成的各种离线批处理功能,以及常见的算法,基于Spark RDD的核心编程都可以实现,并且可以更好的、更容易地实现。而且基于Spark RDD 编写的离线处理程序,运行速度是Map Reduce的数倍,速度上有非常明显的优势
Spark相较于MapReduce速度快的最主要原因在于:mapReduce的计算模型太过于死板,必须是map-reduce模式,有时候即使完成一些诸如过滤之类的操作,也必须经过map-reduce过程,这样就必须经过shuffle过程。而MapReduce的shuffle是最消耗性能的,因为shuffle中间的过程必须基于磁盘来读写。而Spark的shuffle虽然也要基于磁盘,但是其大量的transformation操作可以直接基于内存进行pipeline操作,速度性能自然大大提升
但是Spark也有劣势,由于Spark基于内存进行计算,虽然开发容易,但是真正面对大数据的时候,在没有进行调优的情况下,可能会出现各种各样的问题(比如OOM内存溢出)。导致Spark程序可能都无法完全运行起来,就报错挂掉了,而MapReduce及时是运行缓慢,但是至少可以慢慢运行完。
Spark SQL 实际上并不能完全替代Hive,因为Hive是一种基于HDFS的数据仓库,并且提供了基于SQL模型的分布式交互查询引擎
严格的来说,Spark SQL 能够替代的只是Hive的查询引擎,而不是Hive本身,实际上即使在生产环境下,Spark SQL也是针对Hive仓库中的数据进行查询,Spark本身是不提供存储的,自然也不可能替代Hive作为数据仓库
Spark SQL的优点,相较于Hive查询引擎来说,就是速度快,同样的SQL语句,可能使用Hive查询引擎,由于其底层基于MapReduce,必须经过shuffle过程走磁盘,因此速度是非常缓慢的。很多复杂的SQL语句,在hive中执行都需要一个小时以上的时间。而Spark SQL由于Spark自身基于内存的特点,因此速度达到Hive查询引擎的数倍以上
Spark SQL相较于Hive的另一个优点,就是支持大量不同的数据源,包括hive、json、parquet、jdbc等。此外,Spark SQL由于深处Spark技术堆栈内,也是基于RDD来工作,因此可以与Spark的其他组件无缝整合使用,配合起来实现许多复杂的功能。比如Spark SQL 支持可以直接针对hdfs文件执行sql语句
Spark Streaming 与 Storm都可以进行实时流计算,但是两者的区别是非常大的。其中区别之一就是,Spark Streaming 和 Storm的计算模型完全不一样,Spark Streaming是基于RDD的,因此需要将一段时间内的数据收集起来,作为一个RDD,然后再针对这个batch的数据进行处理。而Storm却可以做到每来一条数据,都可以立即进行处理和计算,因此,Spark Streaming 实际上只能称作准实时的流计算框架,而Storm是真正意义上的实时计算框架
此外,Storm支持的一项高级特性,是Spark Streaming暂时不具备的,即Storm支持分布式流式计算程序在运行的时候,可以动态地调整并行度,从而动态提高并发处理能力。而Spark Streaming 是无法动态调整并行度的
但是Spark Streaming 由于也身处Spark生态圈内,因此Spark Streaming 可以与Spark Core、Spark SQL,甚至是Spark MLlib、Spark GraphX进行无缝整合。流式处理完的数据,可以立即进行各种的map、reduce转换操作,可以立即使用sql进行查询,甚至可以立即使用machine learning(机器学习)或者图计算算法进行处理,这种一站式的大数据功能和优势,是Storm无法匹敌的
因此,综合上述来看,通常在对实时性要求特别高,而且实时数据量不稳定,比如白天有高峰的情况下,可以选择使用Storm,但是如果对实时性要求一般,允许1秒的准实时处理,而且不要求动态调整并行度的话,选择Spark Streaming是更好的选择
首先,Spark相较于MapReduce来说,可以立即替代的,并且会产生非常理想的效果,就是要求低延时的复杂大数据交互式计算系统。比如某些大数据系统,可以根据用户提交的各种条件,立即定制执行复杂的大数据计算系统,并且要求低延时(一个小时以内)即可以出来结果,并且通过前端页面展示效果。在这种场景下,对速度比较敏感的情况下,非产生过hi和立即使用Spark替代MapReduce。因为Spark编写的离线批处理程序,如果进行了合适的性能调优之后,速度可能是MapReduce程序的十几倍,从而达到用户期望的效果
其次,相对于Hive来说,对于某些需要根据用户选择的条件,动态拼接SQL语句,进行某类特定查询统计任务的系统,其实类似于上述的系统,此时也要求低延时,甚至希望达到几分钟之内,此时也可以使用Spark SQL替代Hive查询引擎,此时使用Hive查询引擎可能需要几十分钟执行一个复杂的SQL,而使用Spark SQL ,可能只需要使用几分钟就可以达到用户期望的效果
最后,对于Storm来说,如果仅仅要求对数据进行简单的流式计算处理,那么选择Storm或者Spark Streaming都无可厚非,但是如果需要对流式计算的中间结果(RDD),进行复杂的后续处理,则使用Spark更好,因为Spark本身提供了很多功能。
分布式
主要基于内存(少数情况基于磁盘)
迭代式计算
- RDD是Spark提供的核心抽象,全称为Resillient Distributed Dataset,即弹性分布式数据集
- RDD在抽象上来说是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群上的不同节点上,从而让RDD中的数据可以被并行操作(分布式1数据集)
- RDD通常通过Hadoop上的文件。即HDFS文件或者Hive表,来进行创建,又是也可以通过应用程序的集合来创建
- RDD最重要的特性就是,提供了容错性,可以自定从节点失败中恢复过来。机器如果某个节点上的RDD partition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition
- RDD的数据默认情况下存放在内存中,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性)
- 核心开发:离线批处理
- SQL查询:底层都是RDD和计算操作
- 实时计算:底层都是RDD和计算操作
- 需求分析
- 开发:
- 添加Spark的maven依赖
- 推荐在Idea中开发
- 执行
- 直接在idea中执行(不推荐)
- 使用spark-submit提交到集群执行
- 使用spark-shell进行调试执行
-
针对Spark on yarn模式的配置
-
选择一台Spark客户端机器,启动Spark的historyServer进程
-
修改spark-defaults.conf 配置文件
-
启动:
sbin/start-history-server.sh
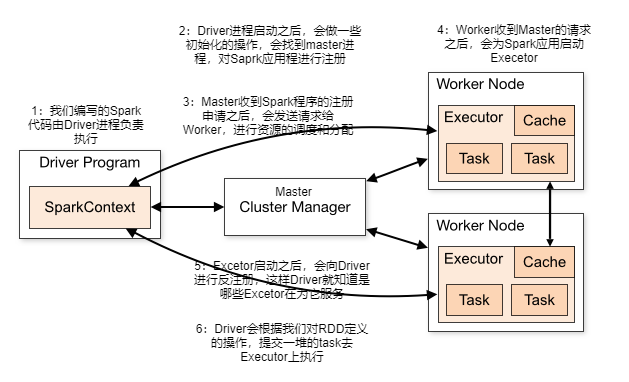
- Driver
- 编写的Spark程序就在Driver(进程)上,由Driver进程负责执行
- Driver进程所在的节点可以是Spark集群的某一个节点(cluster启动)或者就是提交Spark程序的机器(client启动)
- Master
- 集群主节点中启动的进程
- 主要负责资源管理和分配,还有集群的监控
- Worker
- 集群从节点中启动的进程
- 主要负责启动其他进程来执行具体的数据处理和计算
- Executor
- 是一个独立的进程
- 此进程由Worker负责启动,主要为了执行数据处理和计算
- Task
- 是一个线程
- 由Executor负责启动,真正执行数据处理和计算的
 )
)
进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD。这样就相当于设置了Spark应用程序的输入源数据。然后再创建了初始的RDD之后,才可以通过Spark Core提供的transformation算子,对该RDD进行转换,来获取其他的RDD
Spark Core提供了三种创建RDD的方式
-
使用程序中的集合创建RDD
主要是用于程序测试,可以在实际部署到集群之前,自己使用集合构造测试数据,来测试后面的Spark应用的流程
-
使用本地文件创建
主要用于临时性地处理一些存储了大量数据的文件
-
使用HDFS文件创建
最常用的生产环境处理方式,主要可以针对HDFS上存储的数据,进行离线批处理操作
- 如果要通过并行化集合来创建RDD,需要针对程序中的集合,调用Spark Context的parallelize() 方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。相当于是,集合中的部分数据回到一个节点上,而另一部分数据回到其他节点上。然后就可以用并行的方式操作这个分布式数据集合,即RDD
- 调用parallelize()时,有一个重要的参数可以指定,就是要将集合切分成多个partition。Spark会为每一个partition运行一个task来进行处理。Spark官方的建议是,为集群中的每个CPU创建2~4个partition。Spark会默认根据集群来设置partition的数量。但是也可以在调用partition()方法时,传入第二个参数,来设置RDD的partition数量。比如,parallelize(arr,10)
-
Spark是支持使用任何Hadoop支持的存储系统上的文件创建RDD的,比如HDFS、Cassandra、Hbase以及本地文件
-
通过调用SparkContext.textFile()方法,可以针对本地文件或HDFS文件创建RDD
注意事项:
- 如果是本地文件的话,在windows中测试只有一份数据即可。但是如果是在Spark集群中执行,需要集群中的所有worker节点都存在一份该文件
- Spark的textFile()方法支持目录、压缩文件以及通配符进行RDD创建
- Spark默认会为hdfs文件的每个block创建一个partition,但是也可以通过textFile()的第二个参数手动设置分区数量,partition数量只能比block数量多,不能比block数量少
-
SparkContext还有一些特例的方法来创建RDD
-
SparkContext.wholeTextFiles()方法,可以针对一个目录中的大量小文件,返回<filename.fileContent>组成的pair,作为一个PairRDD,而不是普通的RDD。普通的textFile()返回的RDD中,每个元素就是文件中的一行文本
-
SparkContext.sequenceFile[K,V]方法,可以针对SequenceFile创建RDD,K和V泛型类型就是SequenceFile的key和value的类型,K和V要求必须是Hadoop的序列化对象,比如IntWritable、Text等
-
SparkContext.hadoopRDD()方法,对于Hadoop的自定义输入类型,可以创建RDD
-
SparkContext.objectFile()方法,可以针对之前调用RDD.saveAsObjectFile()创建的对象序列化的文件,反序列化文件中的数据,并创建一个RDD
Spark支持两种RDD操作:transformation和action
-
transformation操作会对已有的RDD创建一个新的RDD
-
而action则主要是对RDD进行最后的操作,比如遍历、reduce、保存到文件等,并可以返回结果给Driver程序
-
map是一种transformation操作,它用于将已有RDD的每个元素传入一个自定义的函数,并获取一个新的元素,然后将所有的新元素组成一个新的RDD。
-
而reduce就是一种action操作,它用于对RDD中的所有元素进行聚合操作,并获取一个最终的结果,然后返回给Driver程序。
transformation的特点就是lazy特性
lazy特性指的是,如果一个Spark应用中只定义了transformation操作,那么即使执行该应用,这些操作也不会执行。也就是说,transformation是不会触发Spark程序的执行,它们只是记录了对RDD所做的操作,但是不会自发地执行。只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行。Spark通过这种lazy特性,来进行底层的Spark应用执行的优化,避免产生过多的中间结果。
action操作执行,会触发一个Spark Job的运行,从而出发这个action之前所有的transformation的执行。这是action的特性
- map
- 将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD
- filter
- 对RDD中的每个元素进行判断,如果返回true则保留,返回faalse则移除
- flatMap
- 与map类似,但是对每个元素都可以返回一个或多个新元素
- groupByKey
- 根据key进行分组,每个key对应一个Iterable
- reduceByKey
- 对每个key对应的value进行reduce操作
- sortByKey
- 对每个key对应的value进行排序操作
- join
- 对两个包含<key,value>对的RDD进行join操作,每个key join上的pair,都会传入自定义函数进行处理,可能一个key会有多个结果<key,value>
- cogroup
- 同join,但是每个key对应的Iterator都会传入自定义函数进行处理,每个key只会返回一行数据,value为Iterator集合类型的<key,Iterator>
-
reduce
- 将RDD中的所有元素进行聚合操作,第一个和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推,直至结束
-
count
- 获取RDD元素总数
-
countByKey
- 对每个key对应的值进行count计数
-
foreach
- 遍历RDD中的每个元素
-
saveAsTextFile
- 将RDD元素保存到文件中,对每个元素调用toString方法
-
collect
-
将RDD中所有元素获取到本地客户端
生产环境下不建议使用,会将所有的数据加载到Driver端,除非确定返回的值很小
-
-
take
- 获取RDD中指定个数的元素
- Spark中非常重要的一个功能特性就是可以将RDD持久化到内存中,当对RDD执行持久化操作时,每个节点都会将自己操作的RDD的partition持久化到内存中,并且在之后对该RDD的反复使用时,直接使用内存缓存的partition。这样的话,对于针对一个DD反复执行多个操作的场景,就只要对RDD计算一次即可,后面直接使用该RDD,而不需要反复多次计算该RDD
- 巧妙的使用RDD持久化,甚至在某些场景下,可以将Spark应用程序的性能提升10倍。对于迭代式算法和快速交互式应用来说,RDD持久化,是非常重要的。
- 要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接换存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其 源RDD(父RDD),使用transformation操作重新计算该partition。
- cache()和persist()的区别在于,cache()是persist()的一种简化方式,cache()的底层就是调用的persist()的无参版本,同时就是调用persist(MEMORY_ONLY),将数据持久化到内存中。如果需要从内存中清除缓存,那么可以使用unpersist()方法。
- Spark自己也会在shuffle操作时,进行数据的持久化,比如写入磁盘,主要是为了在节点失败时,避免需要重新计算整个过程。
- MEMORY_ONLY
- 以非序列化的Java对象的方式持久在JVM内存中。如果内存无法完全存储RDD所有的partition,那么这些没有持久化的partition就会在下一次需要使用它的时候,重新被计算
- MEMORY_AND_DISK
- 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘获取。
- MEMORY_ONLY_SER
- 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销。
- MEMORY_AND_DISK_SER
- 同MEMORY_AND_DISK,但是使用序列化方式持久化Java对象
- DISK_ONLY
- 使用非序列化Java对象的方式持久化,完全存储到磁盘上。
- MEMORY_ONLY_2和MEMORY_AND_DISK_2
- 如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点上,从而在数据丢失时,不需要再次计算,只需要计算使用备份数据即可。
Spark提供的多种持久化级别,主要是为了在COPU和内存消耗之间进行取舍。
-
优先使用MEMORY_ONLY,如果可以缓存所有数据的话,那么就使用这种策略。
因为纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作
-
如果MEMORY_ONLY策略,无法存储的下所有数据的话,那么使用MEMORY_AND_SER,将数据进行序列化进行存储,纯内存操作还是非常快,只是要消耗soCPU进行反序列化
-
如果需要进行快速的失败恢复,那么久选择带后缀为_2的策略,进行数据的备份,这样在失败时,就不需要重新计算了。
-
能不使用DISK相关的策略,就不使用,有的时候,从磁盘读取数据,还不如重新计算一次
- Spark一个非常重要的特性就是共享变量
- 默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量副本。如果多个task想要共享某个变量,那么这种方式是做不到的
- Spark为此提供了两种共享变量,一种是Broadcast Variable(广播变量),另一种是Accumulator(累加变量)。
- Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝一份,更大的用处是优化性能,减少网络传输以及内存消耗。
- Accumulator则可以让多个task共同操作一份变量,主要可以进行累加操作
- Spark提供的Broadcast Variable,是只读的。并且在每个节点上只有一份副本,而不会为每个task都拷贝一份副本。因此其最大的作用,就是减少变量到各个节点的网络传输消耗,以及在各个节点上的内存消耗。此外,Spark自己内部也使用了高效的广播算法来减少网络消耗
- 可以通过调用SparkContext的broadcast()方法,来针对某个变量创建广播变量。然后再算子的函数内,使用到广播变量时,每个节点只会拷贝一份副本了。每个节点可以使用广播变量的value()方法获取值。广播变量是只读的。
- Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能。但是却提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不饿能读取它的值。只有Driver程序可以读取Accumulator的值。
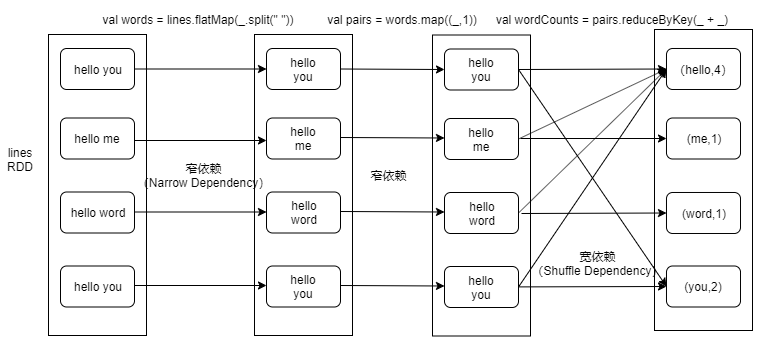
指父RDD的每个分区只能被子RDD的一个分区所使用,例如map、filter、union等操作会产生窄依赖
- 一个RDD,对它的父RDD只有简单的一对一关系,也就是说,RDD的每个partition仅仅依赖于父RDD中的一个partition,父RDD和子RDD的partition之间的对应关系,是一对一的
父RDD的每个分区都可能被子RDD的多个分区所使用,例如groupByKey、sortByKey、reduceByKey等操作会产生宽依赖,会产生shuffle
- 也就是说,每一个父RDD的partition中的数据都可能会传输一部分到下一个RDD的每个partition中。此时就会出现,父RDD和子RDD的partition之间,具有错综复杂的关系,那么,这种情况就叫做两个RDD之间是宽依赖,同时,他们之间会发生shuffle操作。
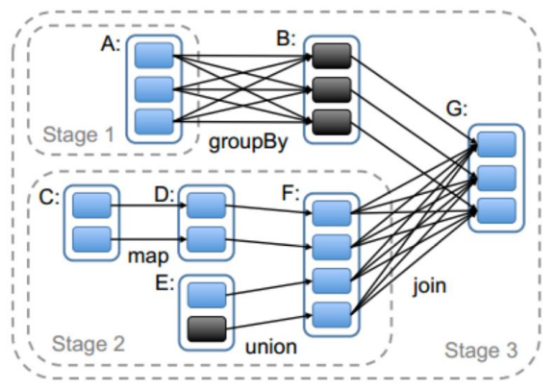
Spark的job是根据action算子触发的,遇到action算子就会起一个job,job里面又划分了很多个stage,然后每一个stage里面运行了很多个task。
Stage的划分依据就是看是否产生了shuffle(即宽依赖),遇到一个shuffle操作就划分为前后两个stage,stage是由一组并行的task组成,stage会将一批task用TaskSet来封装,提交给TaskScheduler进行分配,最后发送到Executor执行。
切割规则:从后往前,遇到宽依赖就切割stage
- 第一种模式,standalone模式,基于Spark自己的Master-Worker集群。
- 指定
--master spark://hadoop100:7077
- 指定
- 第二种,是基于YARN的client模式
- 指定
--master yarn --deploy-mode client - 这种方式主要用于测试,因为driver程序运行在本地客户端,driver负责调度job,会与yarn集群产生大量的通信,从而导致网卡流量激增,并且当执行一些action操作的时候数据也会返回给driver端,driver端机器的配置一般不高,可能会导致内存溢出等问题
- 指定
- 第三种,是基于YARN的cluster模式 <推荐>😄
- 指定
--master yarn --deploy-mode cluster - 这种方式driver程序运行在集群的某一台机器上,不会存在网卡流量激增的问题,并且机器的排至会比普通的客户端机器高
- 指定
### 产生shuffle的场景
- 在Spark中reduceByKey、groupByKey、sortByKey、countByKey、join、cogroup都会产生shuffle(宽依赖)
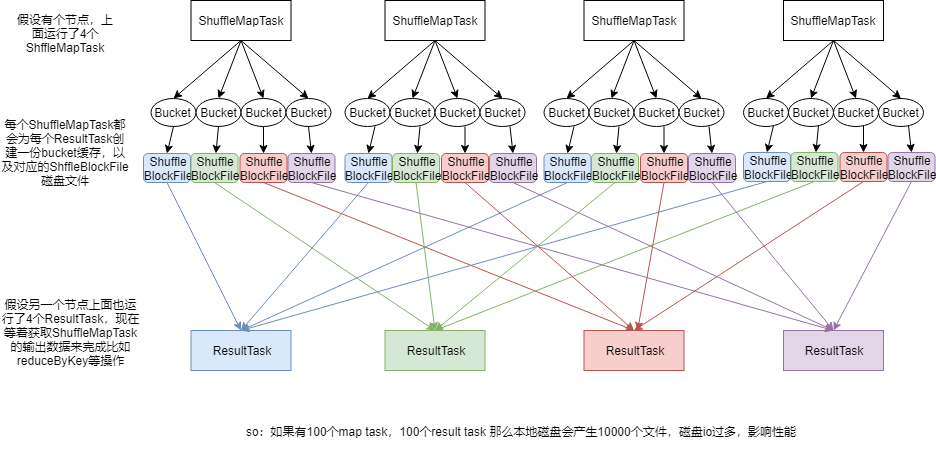
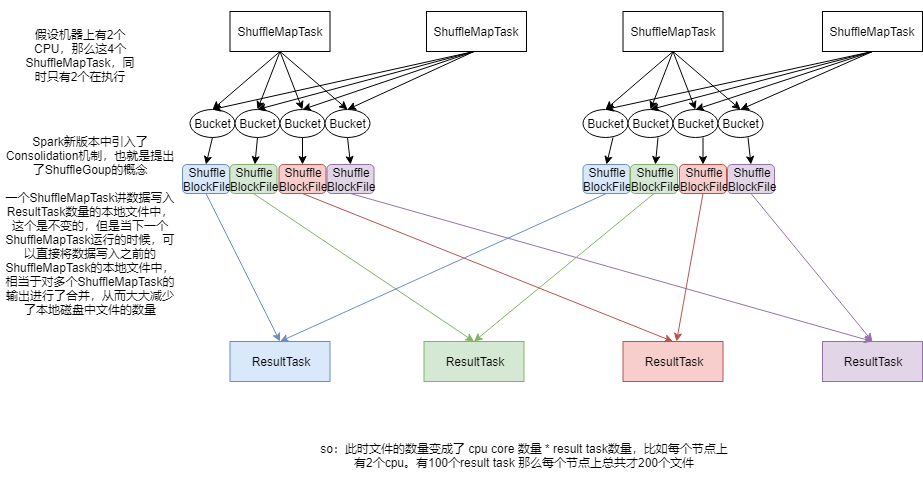
- 第一个特点
- 在Spark早期版本中,那个bucket缓存是非常非常重要的,因为需要将一个ShuffleMapTask所有的数据都写入内存缓存之后,才会刷新到磁盘。但是这有一个问题,如果map side数据过多,那么很容易造成内存溢出。所以Spark在新版本中,优化了,默认那个内存缓存是100KB,当写入的数据达到刷新磁盘的阈值之后,就会将数据刷新到磁盘。
- 这种操作的优点,是不容易发生内存溢出。缺点在于,如果内存缓存过小的话,那么可能发生过多的磁盘IO操作,所以,这里的内存缓存大小,是可以根据实际业务情况进行优化的。
- 第二个特点
- 与MapReduce完全不一样的是,MapReduce它必须将所有的数据都写入本地磁盘文件以后,才能启动reduce操作,来拉取数据。原因是,mapreduce要实现默认的根据key的排序。所以要排序后reduce才能拉取数据
- 但是Spark不需要,Spark默认情况下是不会对数据进行排序的。因此ShuffleMapTask每写入一点数据,ResultTask就可以拉取一点数据,然后再本地执行自定义的聚合函数和算子,进行计算。
- Spark这种机制的好处在于,速度比MapReduce快多了但是也有一个问题,mapreduce提供的reduce,是可以处理每个key对应的value上的数据,很方便。但是Spark中,由于这种实时拉取的机制,因此提供不了直接处理key对应的values的算子,只能通过groupByKey,先shuffle,然后用map算子,来处理每个key对应的values。就没有mapreduce的计算模型那么方便。
- CheckPoint,是Spark提供的的一个比较高级的功能。有的时候,Spark应用程序,特别的复杂,从初始的RDD开始,到最后整个应用程序完成,有非常多的步骤,比如超过50个transformation操作,而且,整个应用运行的时间也特别长,通常要运行5~6个小时。
- 在上述情况下,就比较合适使用checkpoint功能。因为对于特别复杂的Spark应用,有很高的风险,会出现某个要反复使用的RDD因为节点的故障导致丢失,虽然之前持久化过,但是还是导致数据丢失了。那么也就是说,出现失败的时候,没有容错机制,所以当后面的transformation操作,又要使用到该RDD时,就会发现数据丢失了,此时如果没有进行容错处理的话,那么可能就又要重新计算一个数据。
- 简而言之,针对上述情况,整个Spark应用程序的容错性很差
- 所以,针对上述复杂的Spark应用的问题(没有容错机制的问题)。就可以使用checkpoint功能。
- checkpoint就是说,对于一个复杂的RDD chain,如果担心中间某些关键的、在后面会反复几次使用的RDD,可能会因为节点的故障,导致持久化数据的丢失,那么就可以针对该RDD格外启动checkpoint机制,实现容错和高可用
- checkpoint,首先要调用SparkContext的setCheckpointDir()方法,设置一个容错的文件系统的目录,比如说HDFS,然后,对RDD调用checkpoint()方法。之后,在RDD所处的job运行结束后,会启动一个单独的job,来将checkpoint过的RDD的数据写入之前设置的文件系统,进行高可用、容错的雷持久化操作
- 那么此时,即使后面使用RDD时,它的持久化的数据,不小心丢失了,但是还是可以从它的checkpoint文件中直接读取其数据,而不需要重新计算(CacheManager)
- 如何进行checkpoint
- SparkContext.setCheckPointDir()
- RDD.checkpoint()
- Checkpoint与持久化的不同
- 持久化,只是将数据保存到内存中,RDD的lineage(依赖关系)是不变的
- 但是checkpoint执行之后,RDD就没有之前所谓的依赖RDD了,也就是它的lineage改变了
- 持久化的数据丢失的可能性较大,可能丢失
- checkpoint的数据通常是保存在高可用的文件系统中(HDFS),所以丢失的可能性很低
- 给要checkpoint的RDD,先执行persist(StorageLevel.DISK_ONLY)操作